The server saga continues! Last time I ranted about getting things setup physically, this time we’re jumping into the software. Oh don’t worry, I’ll still squeeze 3D printing in somewhere 🙂 As an novice sysadmin, I try my best to follow the core tenants at keeping a server alive. Redundancy, Fault Tolerance and Backups. In my existing setup I have zero redundancy, meaning if anything craps out i’m pulling from my backups. My drives were fault tolerant but nothing else, so again any hardware failure and its a rebuild.

I do have backups through Virtualmin, but if anything were to break at the OS or Hypervisor level, I’m rebuilding a lot of stuff from scratch. With this Enterprise grade hardware, I can patch all these pitfalls. I can setup a real rough and durable stack. Lets start with Clustering.
Drumming up the Drives
The biggest pitfall to cover is hardware. Out of the box, the servers that I acquired have redundant Power supplies, physical RAID Controllers and multiple NIC’s. However, for my primary server, I had to acquire some drive caddies, and by acquire I mean print. Luckily, Thingiverse had a model on hand as always. There was even a remix where no screws are required, just snap and plug.






I printed out the entire array but for now I’m just popping in 3 drives to get minimum fault tolerance. Moving onto the configuration of the array, turned off the physical controller and switched it to HBA mode so I can run ZFS-1. After that, I setup the same configuration as my secondary node. Except, for whatever reason, HP servers do not like running ZFS. While sitting idle, the server load was constantly at 1.00.

Without much luck from Google, I decided the easier route was to just go with the physical controller for HP. and reinstall PVE. When the server came back online, things were running just as smooth as my primary node!
Knotting the NICs
Another redundancy I added for hardware was teaming or bonding the NIC cards. Each server had 4 NICs, which to me was overkill on both throughput and availability, so I settled for just 2. However, this is where I learned that the type of bond you select matters.

For example, picking Active-Backup sounds good at face value, but there is a little more to it. It requires you to configure your switch to handle port grouping. That and DHCP will give out IPV4 to one port and IPV6 to the other. So in my case, if my active-backup flipped, IPV6 is active, DNS gets confused and my site goes offline.

I ended up going with Balance-ALB, a load-balancer for IPV4 traffic sent and received. It also lets me skip configuring my switch to handle bonding and lets the NIC do all the heavy lifting.
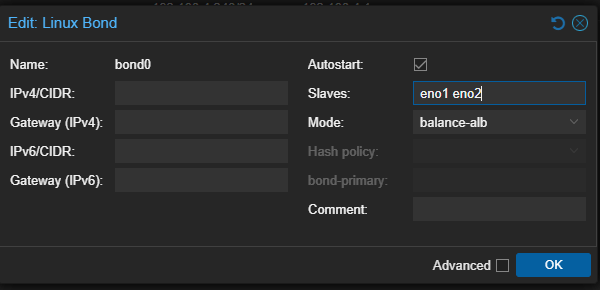
Of course, the best way to know if this works is to just pull the plug and see if you stay up. Luckily for me it worked!
Server Clustering to Avoid a Cluster Fuck
Since the foundation for this entire setup is Proxmox, it would only make sense to take full advantage of everything this product has to offer. While I did explore some of the options in my previous setups, one of the biggest items I missed out on is Clustering.

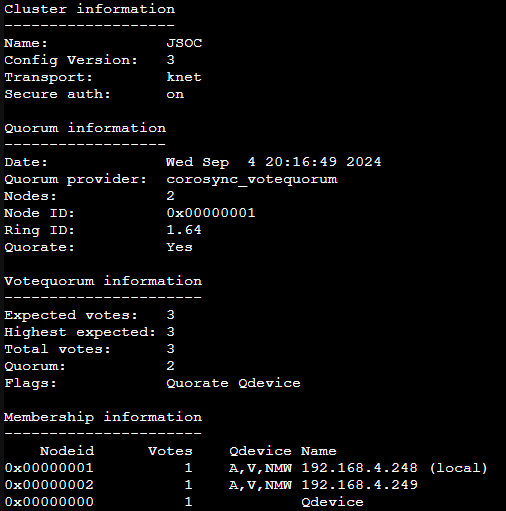
Clustering in Proxmox allows me to log into any of my nodes and have any global changes automatically propagate to the other nodes. Backup Schedules, notifications, Firewall settings, etc, all get synced to every node in the cluster in real-time. Since the nodes are in constant communication, they require dedicated or very fast network between nodes. It’s also recommend to use 3 Nodes per cluster in case one goes offline. If there is only one node left in the cluster, you are no longer in Quorum. Aka, you cannot make global changes, changes always require 2 votes in the cluster.
Because I’m only going to be running two PVE boxes and one Proxmox Backup Server (well get to that in a sec), I’ll only have two nodes in my cluster. However, Proxmox has a workaround, enter QDevices! QDevices is a special package you can put on any Debian box to allow it to cast votes to the cluster. In my case, I can have my Backup server act as a QDevice. So in the event of one of my nodes going down, my backup server can speak up and allow global changes to progress.
One final perk of the cluster I’ll mention is the ability to steam VMs from one node to another. This is ideal when Nodes get unbalanced with VM resources. It gives me the opportunity to re balance them with minimal disruption.
Backups, Backups and More Backups
In every server stack, there is always a backup solution. Possibly even a backup to that backup solution. If you are really paranoid, you can backup your backup with a backup.

Up to this point, all of my Proxmox installs have be PVE (Hypervisors), but for backups we’re going to do something more robust. Proxmox offers a whole separate image to run a full fledged backup server. This isn’t your run of the mill, make a tarball, sql dump and call it a day, oh no no no. This solution takes a VM snapshot and breaks it down into blocks. Why is this cool? Two words, Incremental Backups.

I know right? After the initial backup, every backup from that point forward only compares and uploads chunks that changed. This makes future backup jobs compact and very very fast, unless there are major changes. Restores run just as fast too! With a backup server you can use live restores. During the process the job knows which chunks are OS related and important, so it moves those first. Once those are done, the VM starts and the restore moves over the rest of the chunks in the background as they become available.

The server even comes with verify and pruning jobs. Pruning just lops off old backups that are outside of the set retention period. Verifying just checks that none of the blocks got corrupted during the backup. If any of them did, they are automatically resubmitted.

If that wasn’t enough, you can add on additional storage to the backup server and then run sync jobs to keep your backups backed up. Storage can be local or remote depending on how paranoid you are feeling.
So How Accident Proof is the Server Stack now?
Unfortunately, there isn’t a one size fits solution to be completely invulnerable. Even if you blow a bunch of money on AWS S3 buckets with their stupid high up-time redundancy, a nuclear war is a nuclear war. Something “can” take out your data in one go, its just a matter of how deep do your defenses go.

But, between the Backups, the Cluster, the Bonding, and the Raiding, I’m feeling pretty good. For me, for my personal information, for this hobby of a site, what I have in place is good enough for now. That is until we start doing some real big boy projects that will require the cloud. How does the saying go, cross that bridge till we get there?

Well, with the servers built and the environment sound and secure, we can now move on to filling the stack with VMs. I’m going to call this one a wrap then, until next time!