
Wuddup nerds! Yet again another post not about printing on a 3D printing website. My poor Ender 3 is under the weather and some repairs are needed. Well I need time to do the needed repairs… Eventually the task will bubble to the top of the to do list. Anyway, what I’ve been productively procrastinating with lately is organizing my local music library. Why take on something so boring?

Imagine you have the perfect playlist for snapping necks and cashing checks, then one day some record label decides that it doesn’t want to play with Pandora anymore. Suddenly your playlist has holes in it and now you are just cracking necks and asking for an allowance. Subscriptions = media is rented, you don’t actually own it. At any point in time they can just take it away. This was the shot across the bow for me or was it the shot heard around the world? Either way I was getting shot at and I didn’t like it. It was time to take matters into my own hands and become a homesteader for my own content.
Automate the Cleanup
If you’ve been following this blog, you’ll know that when it comes to managing media my weapon of choice is Plex. And I can already hear you… “Doesn’t Plex automatically organize things for you?!” Yes it does, but Plex can’t organize a shit pile, there needs to be a little bit of structure to it. Ever heard of polishing a turd?

But I’m lazy and I don’t feel like going through every folder and every song, figure out if I like it and make folders, meta data adjustments… UUUUUUUUUUGH… That’s why someone awesome came along and made a program called Beets.

Beets is a cracked out open source media organizer tool with plugins that let you find duplicate tracks, group artists and albums and create a proper folder/file structure for your tunes. You point it to a messy folder, feed it a bunch of parameters of how you want it organized and it gets to work. Here is my config:
directory: /media/music
library: ~/.config/beets/beets.db
import:
move: yes # Don’t move yet—scan only
copy: no # Dont Copy the files
timid: yes # Auto/Manual control
write: yes
incremental: no # CHANGE ME LATER Resume later
log: ~/.config/beets/beetslog.txt
plugins: chroma duplicates fromfilename
duplicates:
check:
import: yes
keys: [mb_trackid, mb_albumid,title,album,albumartist]
fromfilename:
auto: yes
chroma:
auto: yes
paths:
default: $albumartist/$album/$track $title
comp: $albumartist/$album/$track $title
singleton: $artist/Singles/$titleThe Beet Flow
Beets will scan the messy folder, get a thumbprint from the file using FFMEG, send it to Music Brainz (open source Shazam!) and looks for a match. If it finds a nested folder, it will assume its an album and search for that. If its just a folder with a bunch of tracks in them, you can ask it to try to find an album or just search for the individual tracks and dump the results into a Singles folder.
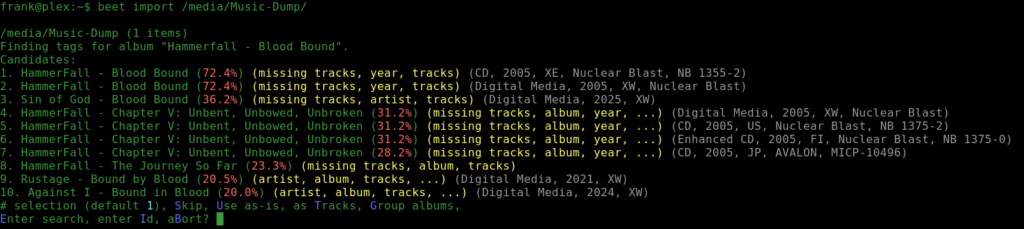
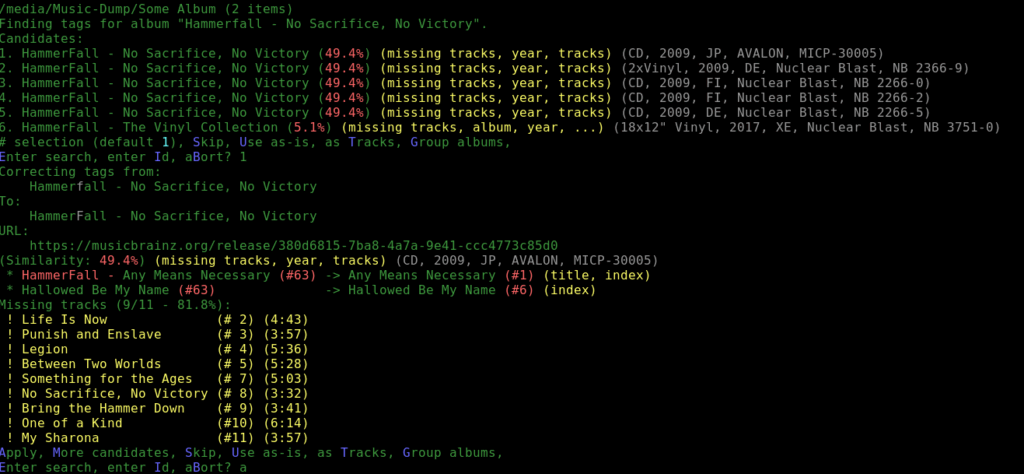
Unfortunately, I have to listen to the songs to see if I like them. Not everything can be automated, at least until we’ve figured out neuro-transmitter logging. So over a few weeks, I’d fire up beets, see the recommendations, listen and decide to skip it or not. I started with ~80GB of tracks and now walked it back to 32GB.

Plex Migration and Music Mapping
Now that I took my turd and polished it into a magnificent golden nugget, I was ready to start organizing on the plex side. This part was actually really easy because Plex’s search and matching is off the charts. The first thing to do is kick off a scan for plex to read the music library. Basically the same thing beets does but now with accurate meta-data and folder structure!
After its done running, I like to look at the albums and sort them by date added. Just by looking at the thumbnails you can get an idea of which ones got matched and which ones still need some help.
But we’re not done yet, this is a revenge story, getting back at those evil subscription corporations that ruined my playlist! Next, I need to rescue the remaining songs from my playlists before any more record labels have a falling out.
The Online Extraction
Services like Pandora and Spotify do have APIs and basic export tools, but nothing that lets me grab all the songs that I’ve collected. In the browser I can see exactly what I want, just no the means to extract it. If only I had access to something that I could tell it what I want and it would write the code for me…

Ah yes, Grok to the rescue! Filling in the gaps of my non-existent JavaScript knowledge with invigorating vibe code. The script I had it write scrolls the thumbed up song page, 25 records at a time since it does lazy loading. It reads a chunk of the page and using regex it pulls out the album, song and URL data.
// Function to extract song data from current DOM, skipping invalid tracks
function extractCurrentSongs(seenHrefs, songData) {
const songLinks = document.querySelectorAll('a.RowItemText[href*="/artist/"]');
songLinks.forEach(link => {
const href = link.getAttribute('href');
if (!seenHrefs.has(href)) {
const parts = href.split('/');
const track = parts[4] || 'unknown';
// Skip if track is 'unknown'
if (track === 'unknown') return;
seenHrefs.add(href);
songData.push({
artist: parts[2] || 'unknown',
album: parts[3] || 'unknown',
track: track,
id: parts[5] || 'unknown',
fullHref: href
});
}
});
return songLinks.length;
}
// Function to scroll and load all songs in sliding window
async function scrollToLoadAll() {
const seenHrefs = new Set();
const songData = [];
let attempts = 0;
const maxAttempts = 3; // Stop after 3 attempts with no new songs
let lastSongCount = 0;
while (attempts < maxAttempts) {
// Extract current batch of songs
const currentSongCount = extractCurrentSongs(seenHrefs, songData);
console.log(`Captured ${songData.length} unique songs so far`);
// If no songs are found, stop
if (currentSongCount === 0) {
console.log('No song links found, stopping.');
break;
}
// Find the last song link to scroll to
const songLinks = document.querySelectorAll('a.RowItemText[href*="/artist/"]');
const lastSongLink = songLinks[songLinks.length - 1];
if (!lastSongLink) break;
// Scroll the last song link to the top to trigger loading new songs
lastSongLink.scrollIntoView({ behavior: 'smooth', block: 'start' });
// Wait for new content to load
await new Promise(resolve => setTimeout(resolve, 2000)); // 2s wait for new batch
// Check if new songs were loaded by comparing unique href count
if (songData.length === lastSongCount) {
attempts++;
console.log(`No new songs loaded, attempt ${attempts}/${maxAttempts}`);
} else {
attempts = 0; // Reset attempts if new songs are added
}
lastSongCount = songData.length;
}
return songData;
}
// Main function to extract and download song data
async function extractSongLinks() {
try {
// Scroll and collect all songs
const songData = await scrollToLoadAll();
// Create JSON string
const jsonData = JSON.stringify(songData, null, 2);
// Create and trigger download of JSON file
const blob = new Blob([jsonData], { type: 'application/json' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = 'song_links.json';
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
console.log(`Extracted ${songData.length} unique songs total`);
} catch (err) {
console.error('Error during extraction:', err);
}
}
// Run the extraction
extractSongLinks();Running it is as easy as having the page up, pulling up the browser Dev-Tools and pasting the code into the console. The script will eventually hit the bottom and run into the same set of songs. After 3 attempts to find anything new it knows that its done. It collects its findings and automatically downloads the list to a JSON file.
Next I have Grok write me a small python script that converts the JSON to a CSV.
import json, csv, re
# Get the data from pandora JSON
with open('pandora-songs.json','r') as f:
data = json.load(f)
# Setup the CSV Tempalte
csvdata = []
headers = ['artist','album','track']
# Go through the JSON and start pushing stuff to the CSV
for i in data:
track = i['track'].replace('-',' ').title()
artist = i['artist'].replace('-',' ').title()
album = i['album'].replace('-',' ').title()
csvdata.append([artist,album,track])
with open('pandora_songs.csv', 'w', encoding='utf-8', newline='') as csvf:
csvwrite = csv.writer(csvf)
csvwrite.writerow(headers)
csvwrite.writerows(csvdata)
for i in csvwrite:
pass
Now I have list of my collected song from the online service, the next step is to get a CSV from my cleaned up Plex server.
The Local Extraction
This ended up being much easier than the online service since I have direct access to the plex database. Plex does everything in SQL lite, a super tiny lightweight database as the name would suggest. Finding it is a lot of fun… Good thing plex tells you
$PLEX_HOME/Library/Application Support/Plex Media Server/Plug-in Support/Databases/com.plexapp.plugins.library.dbThat DB contains all the metadata and customizations you’ve done to your plex library. Its super normalized so to navigate it I needed to use DB Browser for SQL Lite. Again, chatting with Grok, it helped me cook up a query to pull all the data I need to dump it into a CSV.
SELECT
mi.title AS song_title,
pmi.title AS album_title,
gpmi.title AS artist_name,
mp.file AS file_path,
ms.bitrate AS bitrate
FROM media_items m
JOIN metadata_items mi ON m.metadata_item_id = mi.id
JOIN metadata_items pmi ON mi.parent_id = pmi.id -- Parent (album)
JOIN metadata_items gpmi ON pmi.parent_id = gpmi.id -- Grandparent (artist)
JOIN media_parts mp ON m.id = mp.media_item_id
JOIN library_sections ls ON m.library_section_id = ls.id
INNER JOIN media_streams ms ON mp.id = ms.media_part_id -- Require valid bitrate
WHERE ls.section_type = 8 -- Music library
AND ms.bitrate IS NOT NULL -- Explicitly exclude NULL bitratesI threw in Bit-rate results so I can quickly figure out if I have a shitty version of the song. After running the query, I can copy the results and dump them into a spread sheet.
and Voila! We have a spreadsheet with two tabs, one with the online songs and one with the songs that I have. What comes next is some good old spreadsheet filtering.
The Great Music Filter

The easiest way to filter two spreadsheets is by creating index columns. Not sure if that’s the official name but its what I call them. Simply Concatenate several columns into one long string that is unique. For me this is the Artist, Album and Track.
=CONCAT(B1,C1,D1)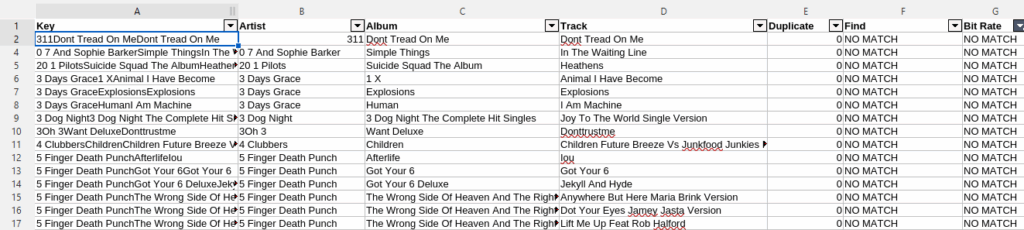
Doing this on both the Plex and Stream sheet, now a VLOOKUP can compare the two values and find matches. Now I can quickly filter the stuff that I’m missing in Plex that I need to shop for.
# For finding the index match
=IFERROR(VLOOKUP(A2,$'Plex Music'.$A$1:$H:$5000,1,0),"NO MATCH")
# For finding the bitrate
=IFERROR(VLOOKUP(A2,$'Plex Music'.$A$2:$F$5000,6,0),"NO MATCH")Vice Versa, I can hunt down songs I already have and figure out if I need to get a better version. I can even look for duplicates in my existing library and get some disk space back. Who wants 5 different versions of “What’s new Pussy Cat”?
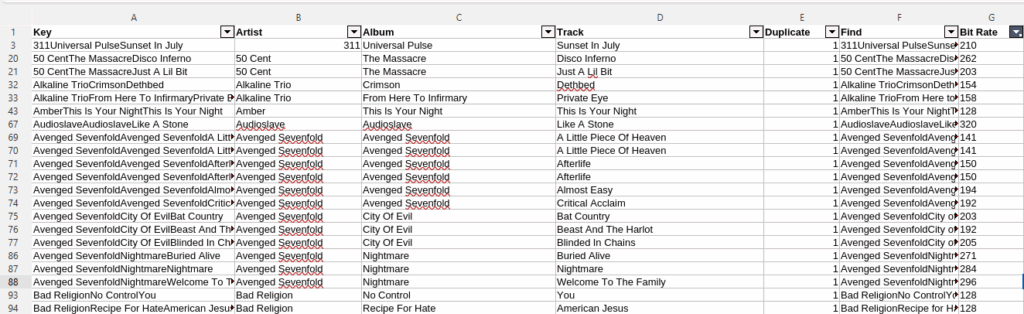
With my songs all filtered and cleaned up, I’m ready to move onto the fun part! Time to go on a shopping spree!! 😀
The Shopping Spree
There are various ways to acquire songs. Personally, I think piracy as a main method of getting media is wrong. If you like the art you need to support it. However, I also believe in ownership and not paying for said media indefinitely. Snow white came out 88 years ago… I think they’ve made their money on it.

That being said, like any technology it can be used for the greater good or for ones personal gain. Like magic glowing rocks! You can make a nuke or a powerplant, the choice is yours. My weapon of choice is Video Downloader.
This fun little tool lets you toss in a URL from a website and then using local python libraries and FFMPEG, it will generate a MP3 or MP4. For audio it defaults to 192Kps which on my shitty stock car speakers, I’m not going to notice.

To really throw this into efficiency overdrive, I can rig up the download location for the app to go directly to my Plex server. Better yet, those files sit in a folder called Music Dump, where via a terminal I have beets analyze the music in that folder. After all the tags are applied and the song is tagged, beets is setup to move the file/folder (if its a whole album), to the music root folder. Creating the proper artist/album paths for it. Making an awesome loop of acquire, beet, and repeat.
Amping things up with Plex AMP
With my music library finally liberated from the greedy grip of record label subscriptions, it was time to kick back and celebrate. Then, in a stroke of serendipity, Plex dropped a bombshell: their main app was getting a major overhaul, spinning off music libraries into a shiny new home. Enter Plexamp, the ultimate media player for your personal tunes.
This isn’t just any player—it’s a love letter to music lovers, packed with trippy visualizers, timed lyrics for your karaoke nights, and cutting-edge sonic analysis that powers custom stations. Want to bridge two wildly different tracks? Pick a metal banger and techno tune, and Plexamp’s virtual DJs will weave a playlist that seamlessly blends the genres. Built with my Plex Lifetime Pass money, Plexamp outshines corporate apps, delivering a nostalgic hit of Windows Media Player on Windows XP—only better.
Ok, fingers crossed my next post is about fixing my damn printer and how I nursed it back to health. In the meantime, enjoy taking control of your music again, stay safe, stay private, stay free out there! Until next time nerds!